La codificación de Huffman es un algoritmo que es usado en la compresión de datos, es una forma de codificación estadistica.
La lóngitud para cada simbolo no es la misma ya que los simbolos utilizados con mas frecuencia se le asignan códigos más cortos mientras que los simbolos menos frecuentes se les asigna un código mas largo.
Ejemplo de como trabaja:
En esta caso dare como entrada una cadena la cual es la siguiente:

Paso 1
Buscamos la frecuencia de los caracteres unicos en el texto anterior:

Paso 2
Cada uno de los caracteres se crea como un arbol y los agrego a una lista, cada arbol tiene su simbolo asociado y su numero de frecuencia.
Paso3 Los ordenamos de menor a mayor según las frecuencias
Paso4
De lo anterior se seleccionaran los primeros dos arboles de la lista y formaremos un nuevo arbol con ellos, antes de realiar el arbol borraremos los dos arboles de la lista:

La raiz del nuevo arbol sera la suma de las frecuencias de las raices de los dos arboles a unir y los arboles seran ahora nodos hijos de esta:

Paso 5
Agregamos a la lista el nuevo arbol creado ordenando de menor a mayor:

Realizamos el paso 4 y 5 de lo anterior hasta que solo quede un arbol en la lista:

.
.

.
.

.
.
.

.
.
.

.
.
.
Paso 6
Ya después de haber obtenido el arbol final tenemos que comenzar a recorrerlo para poder obtener el código binario de cada uno de los caracteres, como es un arbol binario sabemos que tiene las siguientes etiquetas que unen un nodo con otro:

Este árbol contiene las palabras clave nuevas para cada letra, y el nodo raiz que en este caso es el 11 sera el número de caracteres en el texto que son 11.

Paso 7
Convertir el texto original con sus valores de código bianrios por huffman:
Texto origina: Hola alicia
Comprimido: 000001110100101011011101111110
Paso 8
El paso 8 es descomprimirlo, en este caso recorro la cadena ya comprimida caracter por caracter y voi buscando en el arbol si es un cero me voi a la izquierda si es un uno a la derecha hasta encontrar el ultimo nodo que no tenga hijos, ejemplo:

Mi código es el siguiente:
Realice dos pruebas una donde utilizo una gran cantidad de texto en la cadena de entrada pero que los caracteres son repetidos y otro en donde es un texto más pequeño y existen una mayor cantidad de diferentes caracteres:
Mejor Caso:
Texto grande con caracteres identicos mayor, sería el mejor caso ya que no recorreria el arbol muchas veces.:

Texto pequeño con caracteres identicos menor, sería el peor caso ya que el arbol lo recorrera muchas veces por que los caracteres casi no se repiten y son diferentes:
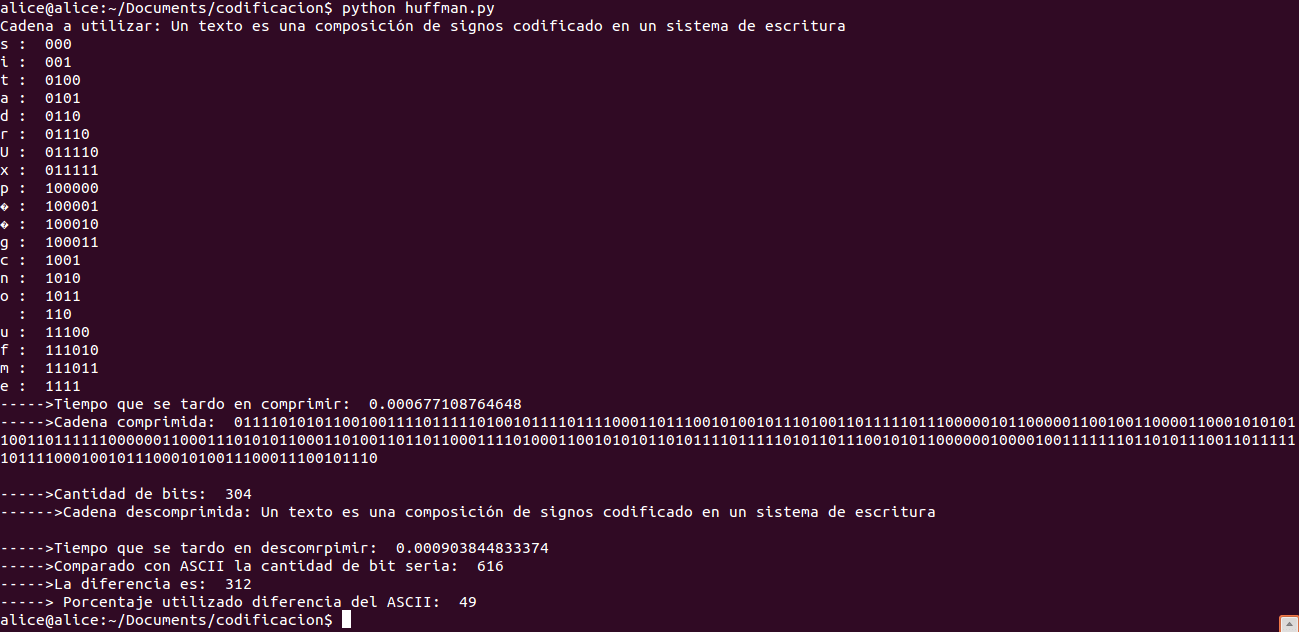
Si nos damos cuenta que mientras más se repita un caracter en una cadena el código dado por el algoritmo de huffman se hace más pequeño.
Y que los caracteres que más se repiten son los que tienen un código binario de menor digitos.
Intenete dibujar el arbol :s pero no alcanse a terminarlo y me lo empalmaba:

Es del ejemplo Hola alicia lo hice con networkx:
Código:
Hubiera sido más útil usar archivos para entrada y salida. Lo haces en ASCII y no en Unicode... El reporte no corresponde a lo que se esperaba ya que habría que hacer algo estadístico y no simples ejemplos. 6+5 pts.
ResponderEliminar